On the Use of Active Learning in Engineering DesignYi Ren (Max) and Panos PapalambrosUniversity of Michigan, Ann Arbor. | IDETC, Chicago, Aug. 15, 2012
Motivation
Many design studies rely on real-world data. For example, we use simulation data in optimization or market data in market share prediction (conjoint analysis). These are regression problems. Jones et al. (1998), Michalek et al. (2005), Frischknecht et al. (2009), and many othersIn other cases, we use classification to identify feasible design regions. Basudhar and Missoum (2010), Malak and Paredis (2010), Alexander et al. (2011) Practical probelm: Acquiring labeled data can be expensive, e.g. through experiments or consumer surveys.Active learning: Start with a small set of labeled data, and iteratively find the most "valuable" queries (a new experiment or survey question) based on current knowledge (the classification or regression model).
Overview
Objective: To review and show commonality of active learning algorithms proposed from computer and marketing sciences;and to compare active learning with D-optimal design on classification and conjoint analysis problems. Things to cover in this talk:
* Exploration vs. exploitation * Active learning in classification and conjoint analysis * Tests and conclusions Exploration vs. exploitation* Definitions of exploratory and exploitative queries * The difficulty of balancing the two
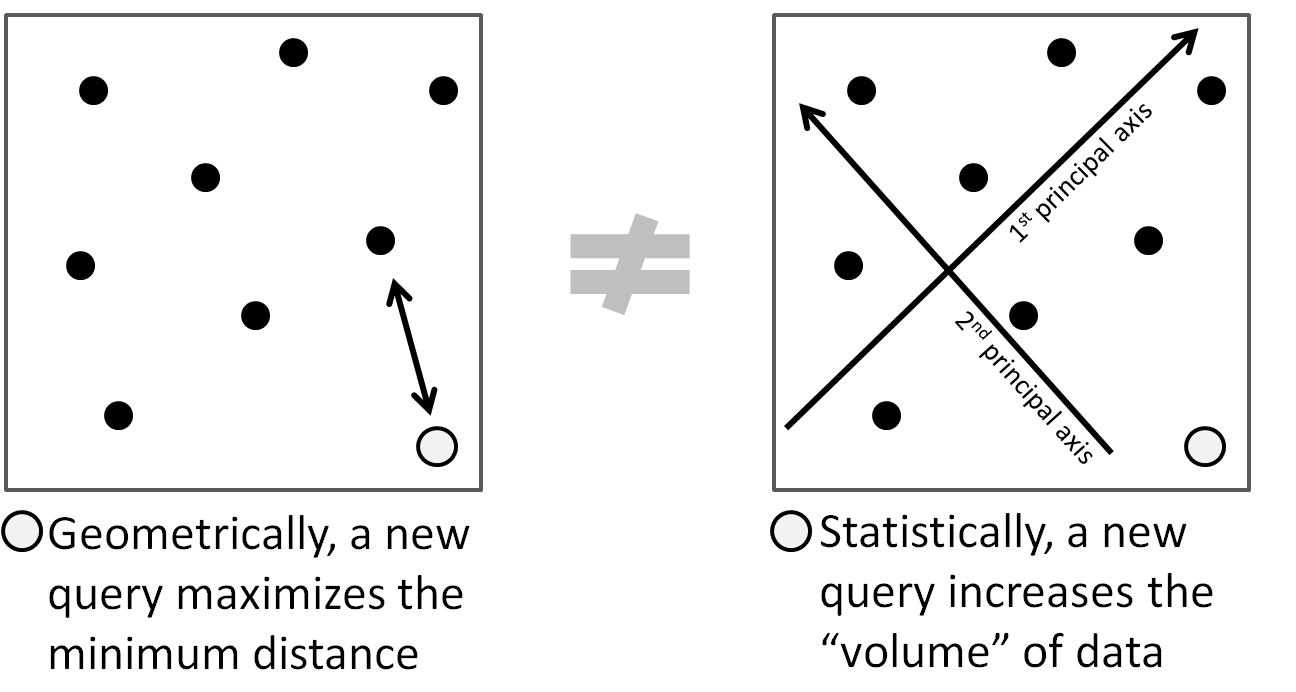
Definition of an exploratory query
Geometrically, an exploratory query is farthest away from previous ones to uncover the design space;
Statistically, it minimizes the variance of the learned model.
An exploratory query does not depend on learning. D-optimal, Latin hypercube designs are exploratory.
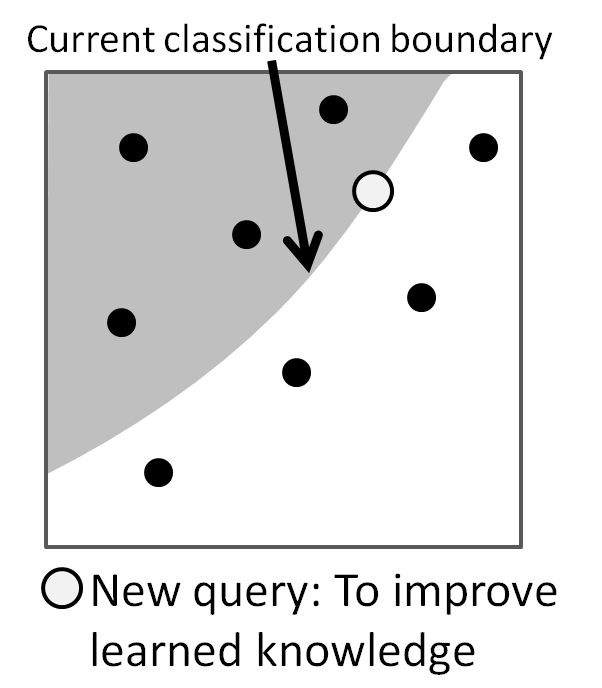
Definition of an exploitative query
An exploitative query is purely based on learned model and aims to improve that model. In a classification problem, an exploitative query on the current decision boundary
will improve the classification.
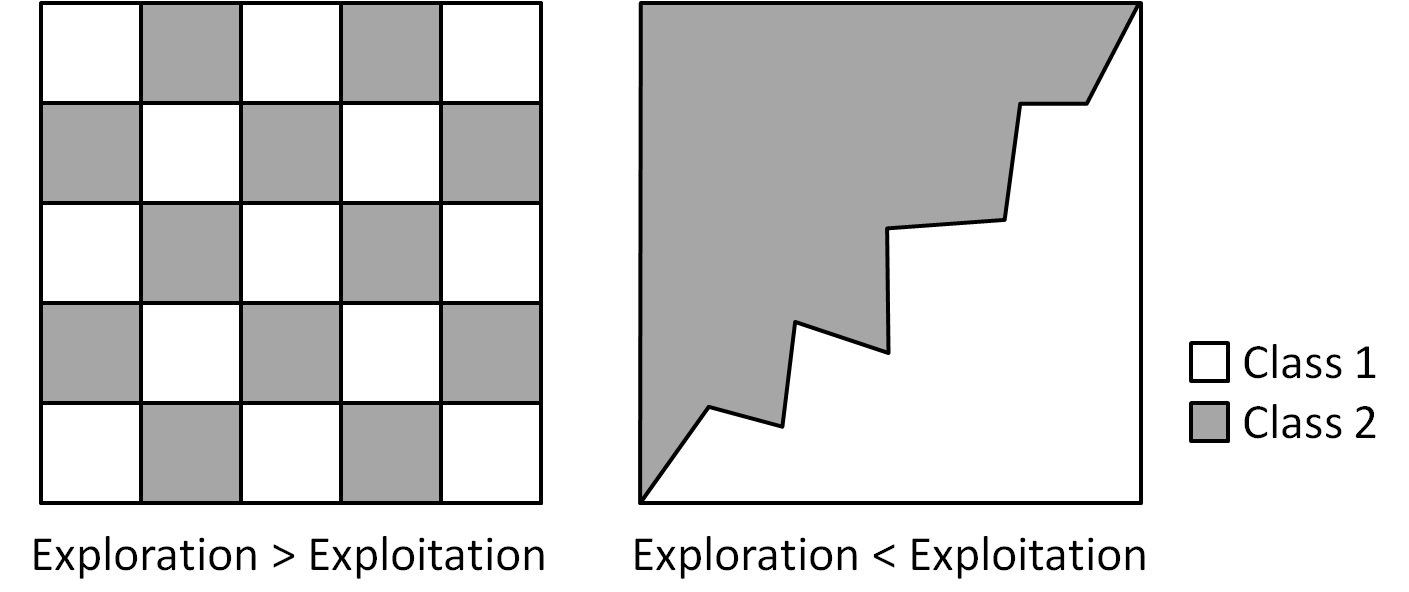
Exploration or exploitation?
The choice is problem-dependent. The difficulty is that we don't know the problem beforehand.
This paper follows existing research to use a fixed exploration-exploitation balance. Other heuristics will be investigated.Active learning in classification (binary) and conjoint analysis* Show the similarity between the two problems * Introduce existing active learning strategies for each problem
Classification problem and its solution
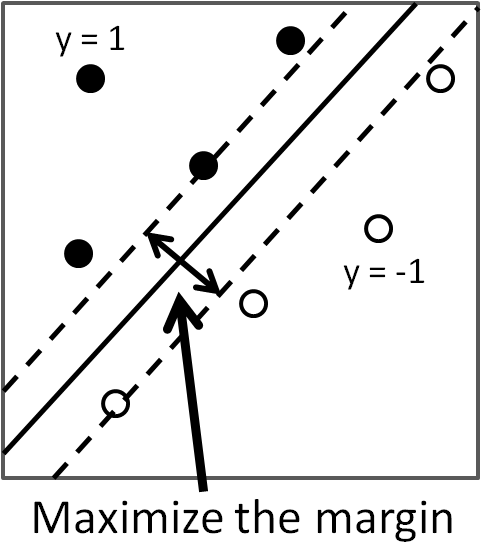
Given data $\{x_i,y_i\}_{i=1}^n$,
assuming a model $y = sign(w^Tx)$, we tune $w$ to maximize the margin between the two classes - a Support Vector Machine solution.Vapnik (1998), Cristianini and Shawe-Taylor (2001)
The SVM formulation maximizes the margin $1/w^Tw$ and minimizes the training error.
Conjoint analysis: A special regression problem, and its solution
Given data $\{x_i\}_{i=1}^n$ and comparison set $\mathcal{I}$.
Assuming a "utility" model $f(x) = w^Tx$. $f(x_{i_1})>f(x_{i_2})$ for any $\{i_1, i_2\} \in \mathcal{I}$. Find $w$ that complies with the observation.
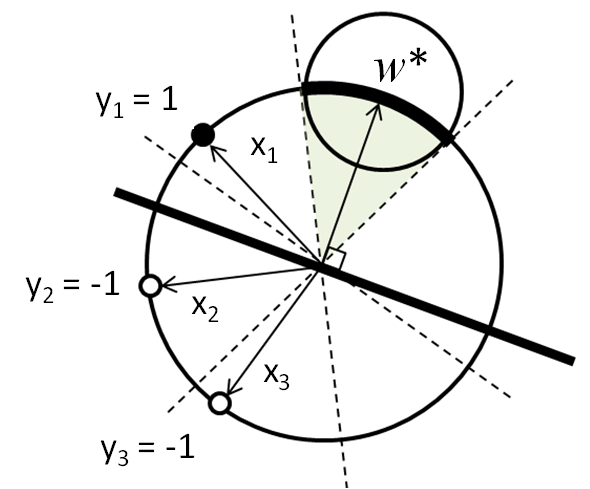
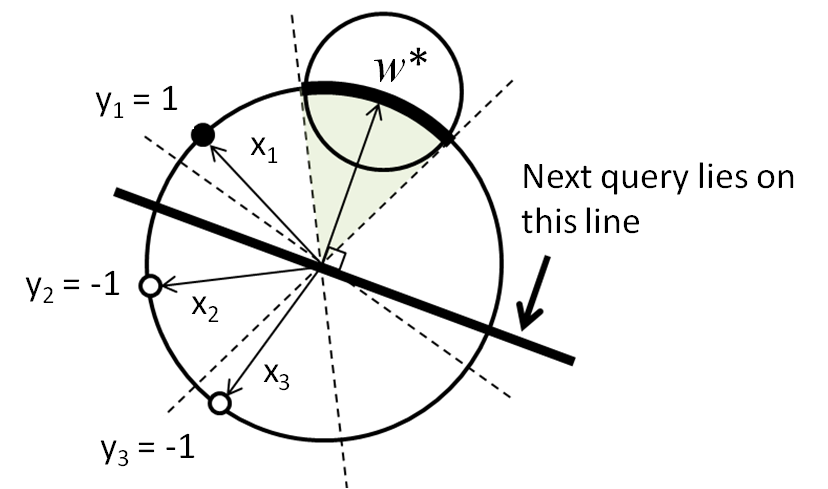
Reduce the feasible space of $w$ as much as you can. Tong and Koller (2001) showed that an exploitative query $x$ is to half the feasible space of $w$. The feasible space of $w$ is defined by $y_iw^Tx_i \geq 0$ and $w^Tw = 1$ (highlighted arc). This can be approximately achieved by $x: ~x^Tw^* = 0$.An exploitative query is on the current decision boundary.
Active learning in conjoint analysis
Theorectically, an exploitative query $z = x_1 - x_2$ tries to decrease the variance of $w^*$. This can be achieved by $z: ~z^Tw^* = 0$. Proof is provided in backup slides.An exploitative query represents two points that cannot be differentiated by the current model.More than one candidate may satisfy the exploitative criterion, therefore an exploratory criterion can be added. Abernethy et al. (2007) proposed to find a query $z$ that is perpendicular to $w^*$ can is in the direction to mostly increase the volume of $H = Z^TZ$. Tests and resultsTo compare active learning with D-optimal design on various problems * Testing algorithm * Test set-up* Results
Testing algorithm, using classification as an example
1. An initial set is labeled.2. Train the current model using the current data to get $w^*$3. Find a query that balances exploitation and exploration
3.1 Calculate the covariance approximation $H = CI+X^TX$ and project it to the plane of $w^*$. C = 1/iteration counter.
3.2 Find $\bar{x}$ as the eigenvector of the second smallest eigenvalue of the projected $H$.
3.3 Derive a new query $x$ with:
$\begin{equation}
x = \mbox{argmin} |x^Tw^*| - |x^T\bar{x}|
\end{equation}$
4. If maximum iteration number not reached, go to 2.This is compared with a D-optimal design. We create a large set of random DOEs and pick the one that has the largest $det(X^TX)$.Candidate queries are mapped to a feature space when a nonlinear model is needed:
$\Phi(x)_i = \exp(-\lambda||x-x_i||^2)$, where $\lambda = $ 1/candidate number.
Binary classification test set-up
The test performance is measured by the error rate:
$\begin{eqnarray}
e = && \mbox{number of wrongly labeled candidates} \\
&&/\mbox{total number of candidates}.
\end{eqnarray}$
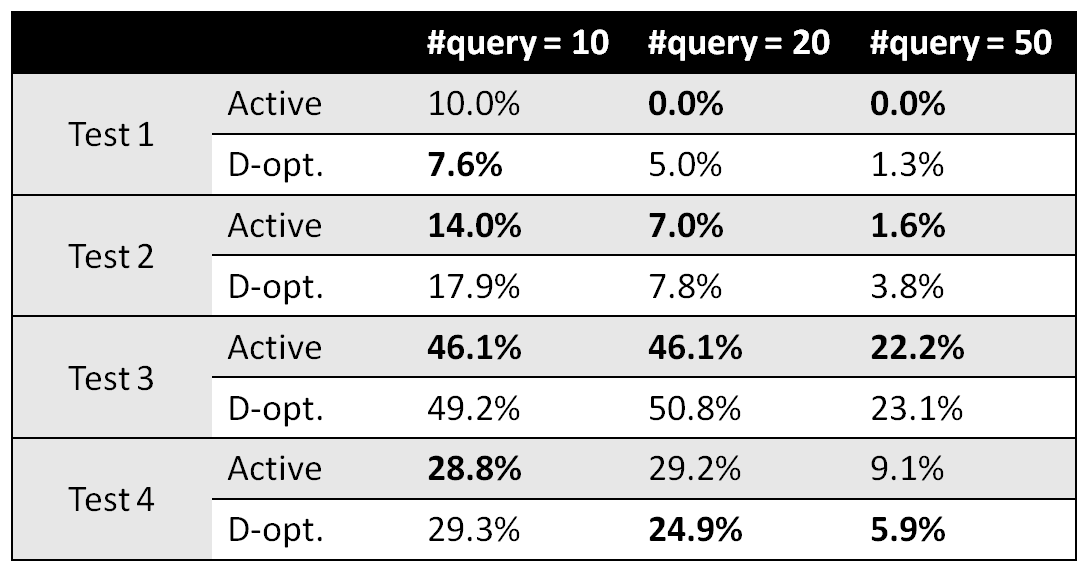
Classification test result
Comparison on mean error rates (lower the better). 100 independent runs per case.
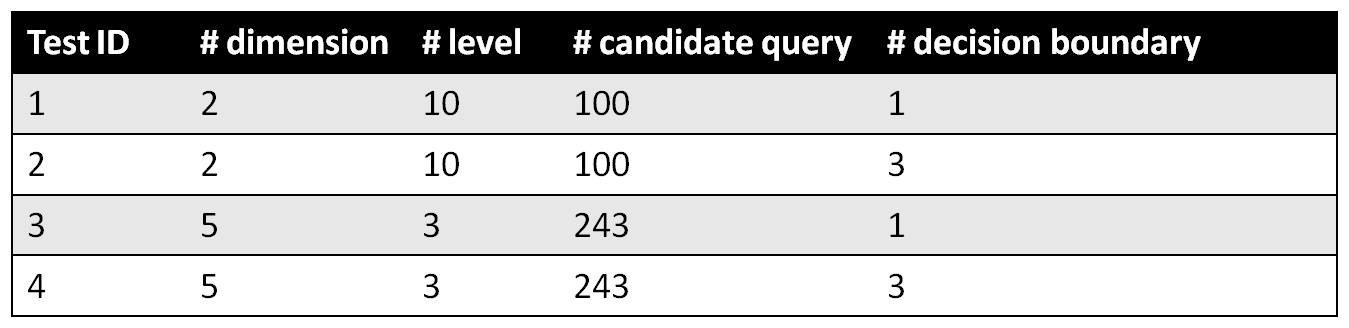
1. Active learning and D-optimal design have similar performance under small query sizes; The former outperforms the latter under large query sizes.
2. Results from test 1 (one boundary to learn) and test 4 (3 disconnected boundaries to learn) demonstrates the case-dependency of exploration vs. exploitation strategies.
Conjoint analysis test set-up
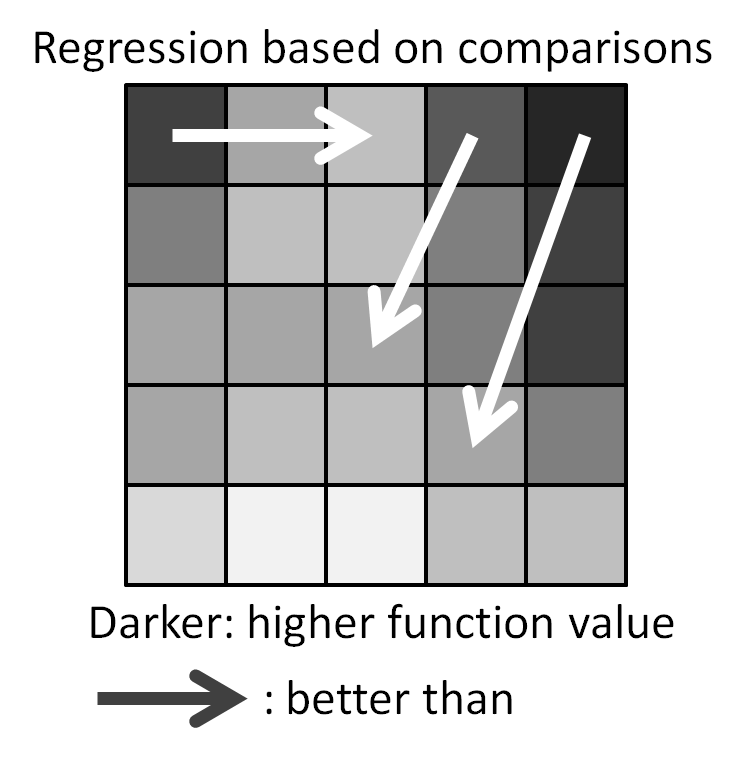
Regression of the following test functions based on pairwise comparisons:
Candidate queries are enumerated pairs from this set (300 in total). Performance is measured by the error rate:
$\begin{equation}
e = \mbox{number of wrongly comparied candidates} /\mbox{total number of candidates}.
\end{equation}$
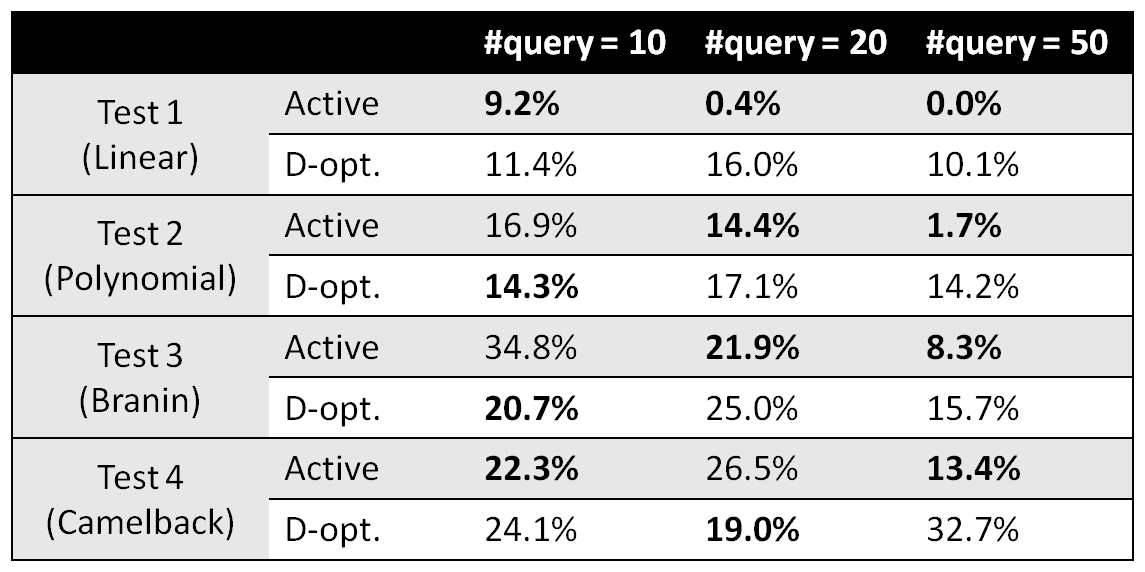
Conjoint analysis test result
Comparison on mean error rates (lower the better). 100 independent runs per case.
Same as in classification: Active learning and D-optimal design have similar performances under small query sizes; The former outperforms the latter under large query sizes.
Conclusions
* Active learning can be useful to design studies relying on data analysis, especially when labels are expensive. * We reviewed theoretical developments of active learning from computer and marketing sciences and showed their similarities. * We showed using various simulation settings that overall active learning improves the learning performance better than D-optimal design along the increase of the query size.
Future work
* The performance of active learning is problem-dependent and relies on tuning the balance between exploration and exploitation. Multi-armed bandit approach will be investigated. presentation available at http://maxyiren.appspot.com/idetc2012b.htmlThank you all for attending. What questions do you have?
Research Fellow Optimal Design Lab University of Michigan yiren@umich.edu maxyiren.appspot.com
Professor Optimal Design Lab University of Michigan pyp@umich.edu ode.engin.umich.edu
Active learning in classification (1/3)
The dual perspective of classification: Denote the feasible space of $w$ as $\mathcal{V}$, defined by $y_iw^Tx_i \geq 0$ and $w^Tw = 1$ (highlighted arc). $w^*$ is the center of the largest sphere in the feasible cone.Tong and Koller (2001)
Active learning in classification (backup 2/3)
In order to efficiently get close to the true $w$, an exploitative query halfs $\mathcal{V}$. Current $w^*$ can be approximated as the center of $\mathcal{V}$. Therefore, a query $x: ~x^Tw^* = 0$ is proposed, i.e., a query on the current boundary is an exploitative query. Tong and Koller (2001)
Active learning in classification (backup 3/3)
More than one candidate may satisfy the exploitative criterion.
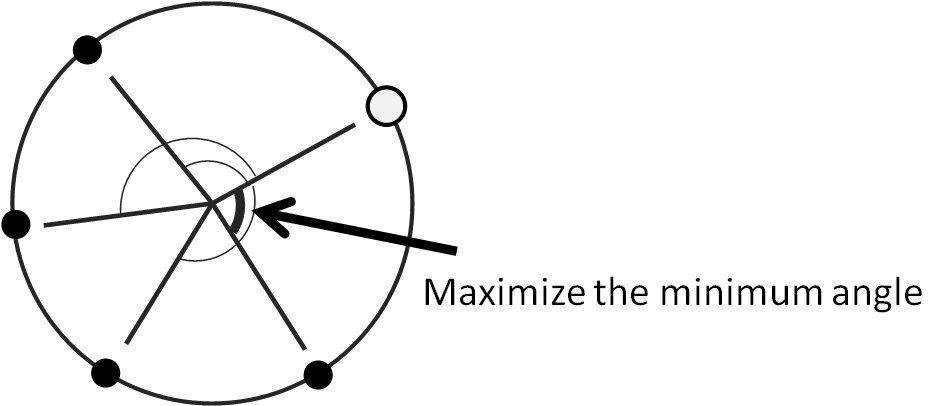
Chang et al. (2005) recommended an exploratory query that maximizes the smallest angle with previous queries $x_i$:
From McFadden (1973), the covariance of estimation $w^*$ is the inverse of the information matrix $\Omega$:
$\Omega = Z^T \mbox{diag}(e_1,...,e_n)Z, \quad n \rightarrow \infty$,
where each row of $Z$ is a pairwise difference: $z_i = x_{i_1} - x_{i_2}$, and
$e_i = \exp(w^Tz_i)/(1+\exp(w^Tz_i))^2$.
Assume $w=0$ (no prior knowledge of the model) to derive the D-optimal design criterion: $\max_Z det(Z^TZ)$.An exploitative query $z: ~z^Tw^* = 0$, maximizing $\exp(z^Tw^*)/(1+\exp(z^Tw^*))^2$,
will increase the determinant of $\Omega$ and reduce the variance of $w^*$.Arora and Huber (2001), Sandor and Wedel (2001) and othersExploitative queries represent two designs that cannot be differentiated by the current model.
Active learning in conjoint analysis (backup 2/2)
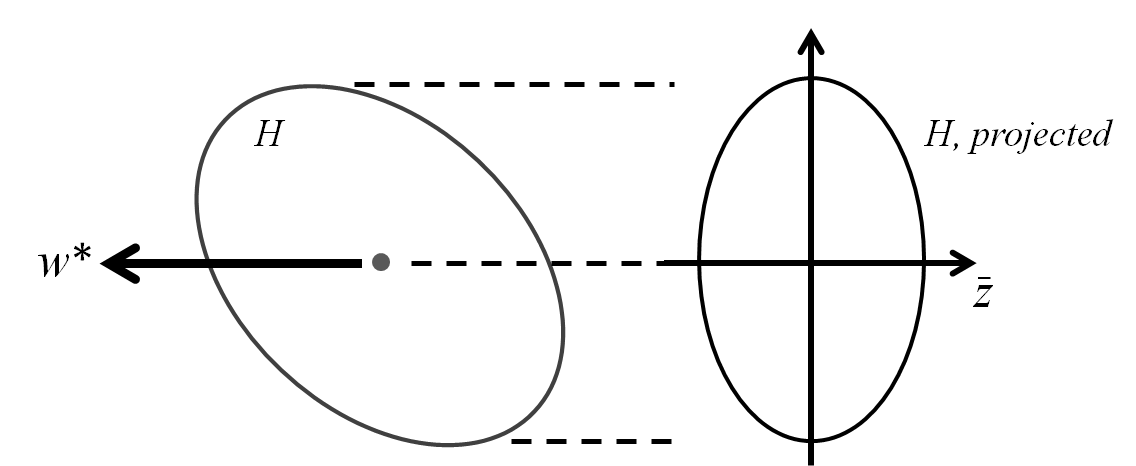
Again more than one candidate may satisfy the exploitative criterion. Abernethy et al. (2007) proposed a regularized approximation of $\Omega$: $H = CI + Z^TZ$, with parameter $C$.Project $H$ to the plane of $w^*$ and denote as $\bar{z}$ the eigenvector associated with the second smallest eigenvalue of the projected $H$.
(The smallest eigenvalue is zero, assoicated with $w^*$) $\bar{z}$ represents the direction with the least data in the plane perpendicular to $w^*$The active learning query $z$ can be derived by:
$\begin{equation}z = \mbox{argmin} |z^Tw^*| - r |z^T\bar{z}|/|z| \end{equation}.$
Summary of the active learning algorithms (backup)
Both machine learning (for classification) and marketing science (for conjoint analysis) have developed active learning algoirthms;Both areas proposed theoretically sound exploitation and exploration schemes. The difficulty of balancing exploitation and exploration is partially addressed by pre-determining a weighting factor. Other heuristics,
e.g., multi-armed bandit method (Baram et al. (2004)), shall be investigated.
Testing algorithm, using classification as an example (backup)
1. An initial set is labeled.2. Train the current model by solving the SVM problem:
3. Calculate the covariance approximation $H = CI+X^TX$ and project it to the plane of $w^*$. C = 1/iteration counter.4. Find $\bar{x}$ as the eigenvector of the second smallest eigenvalue of the projected $H$.5. Derive a new query $x$ with $r = 1$:
$\begin{equation}
x = \mbox{argmin} |x^Tw^*| - |x^T\bar{x}|
\end{equation}$
6. If maximum iteration number not reached, go to 3.This is compared with a D-optimal design. We create a large set of random DOEs and pick the one that has the largest $det(X^TX)$.Candidate queries are mapped to a feature space when a nonlinear model is needed:
$\Phi(x)_i = \exp(-\lambda||x-x_i||^2)$, where $\lambda = $ 1/candidate number.←→