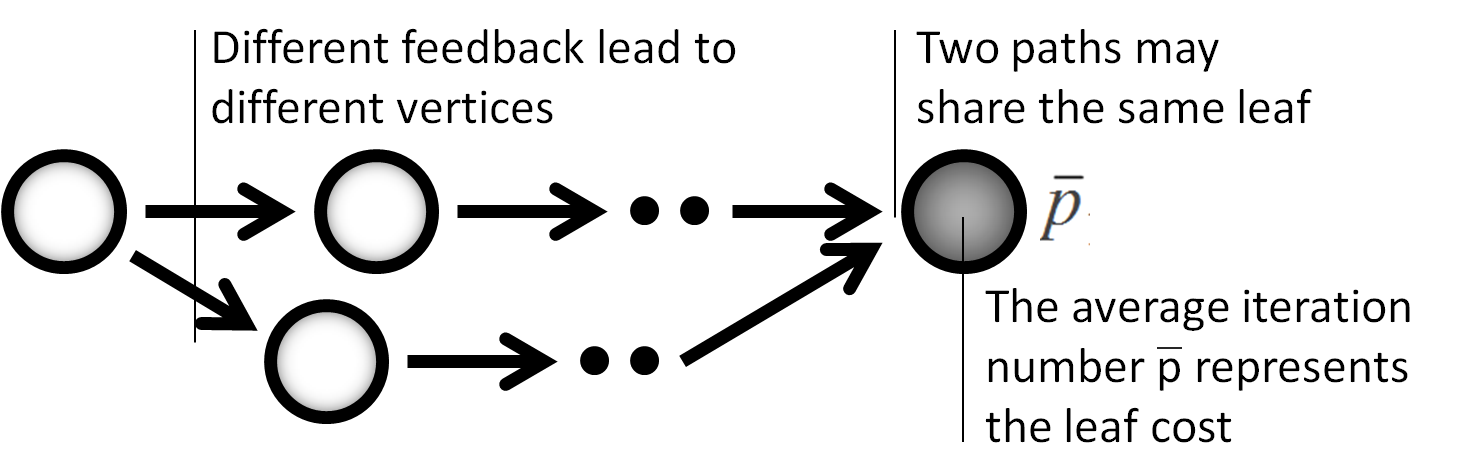
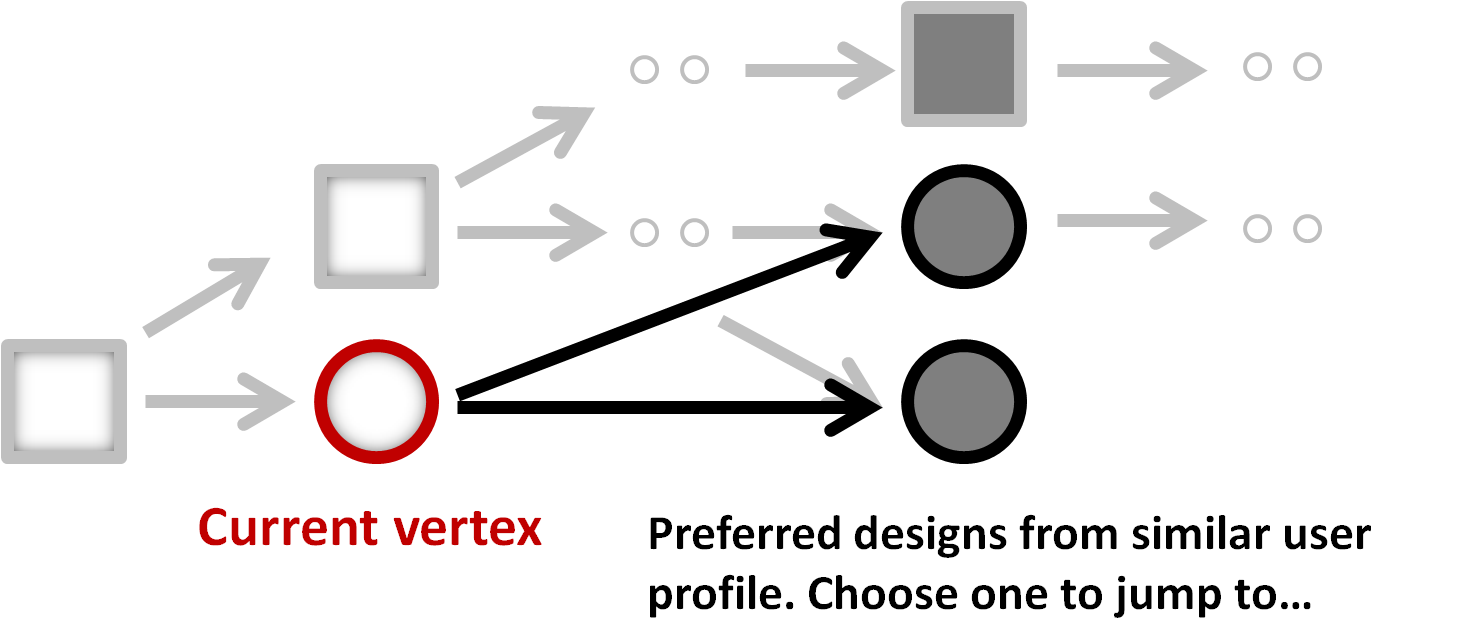
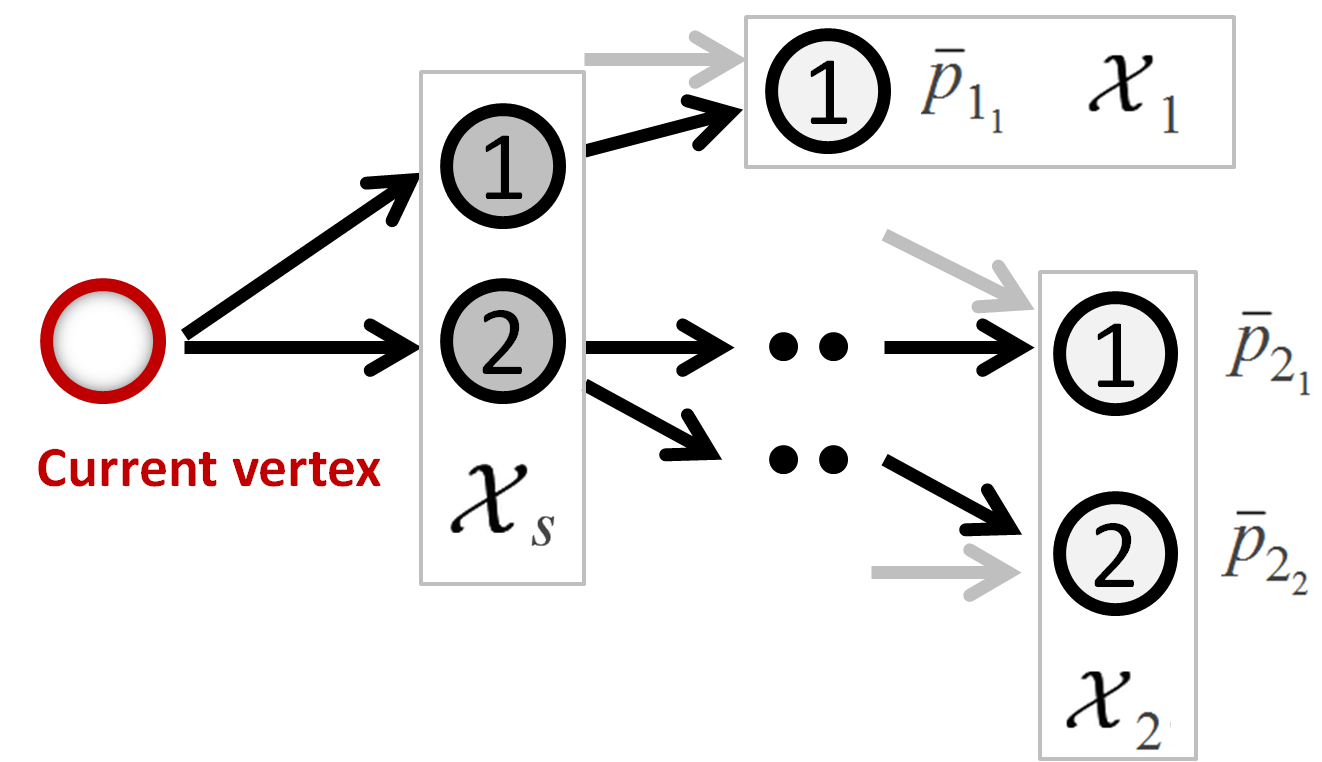
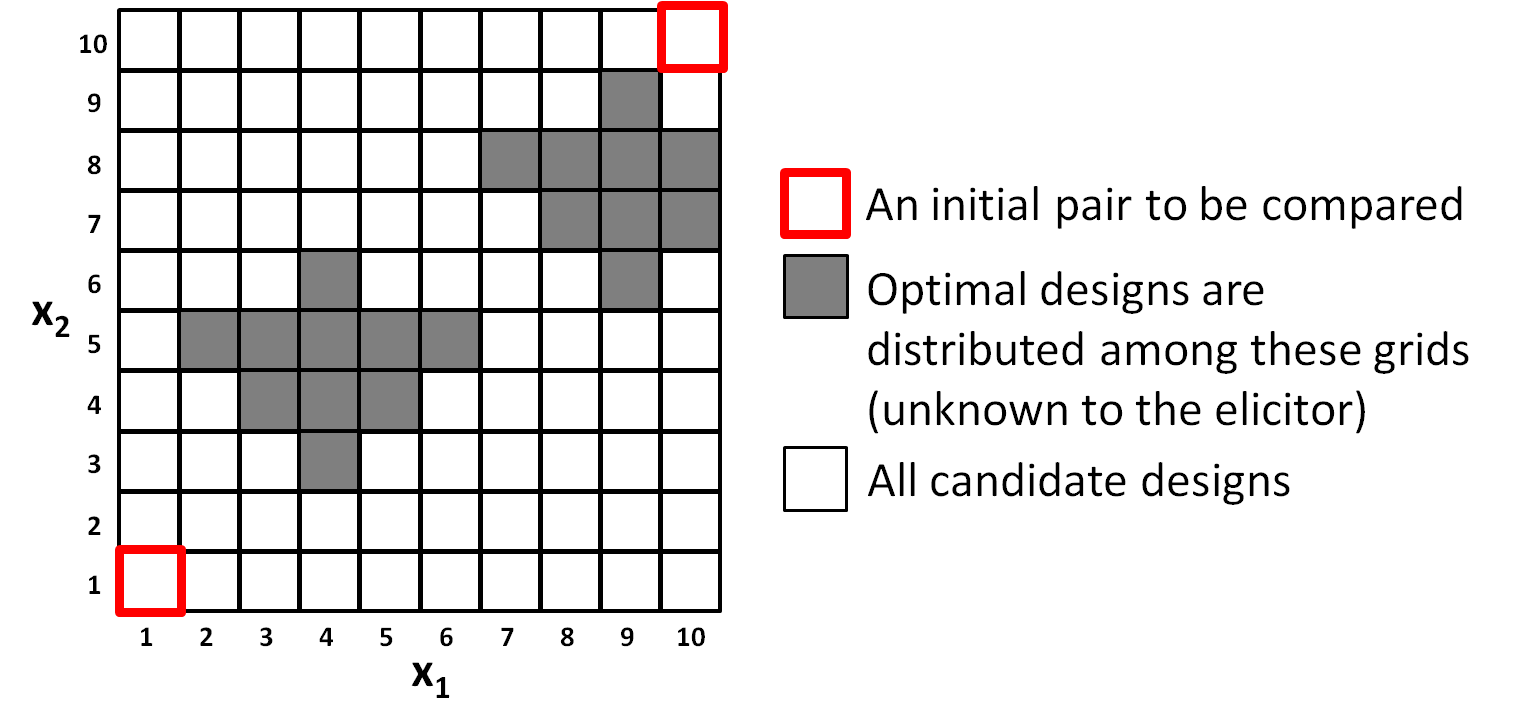
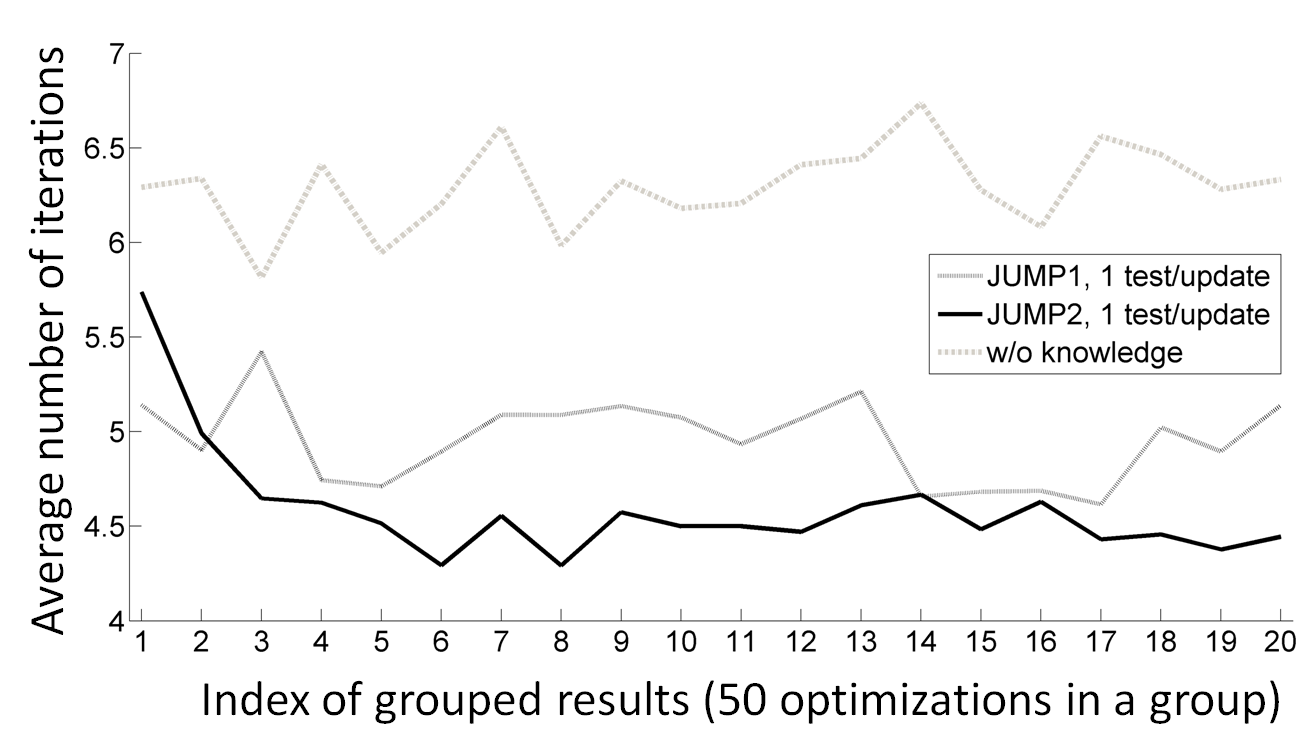
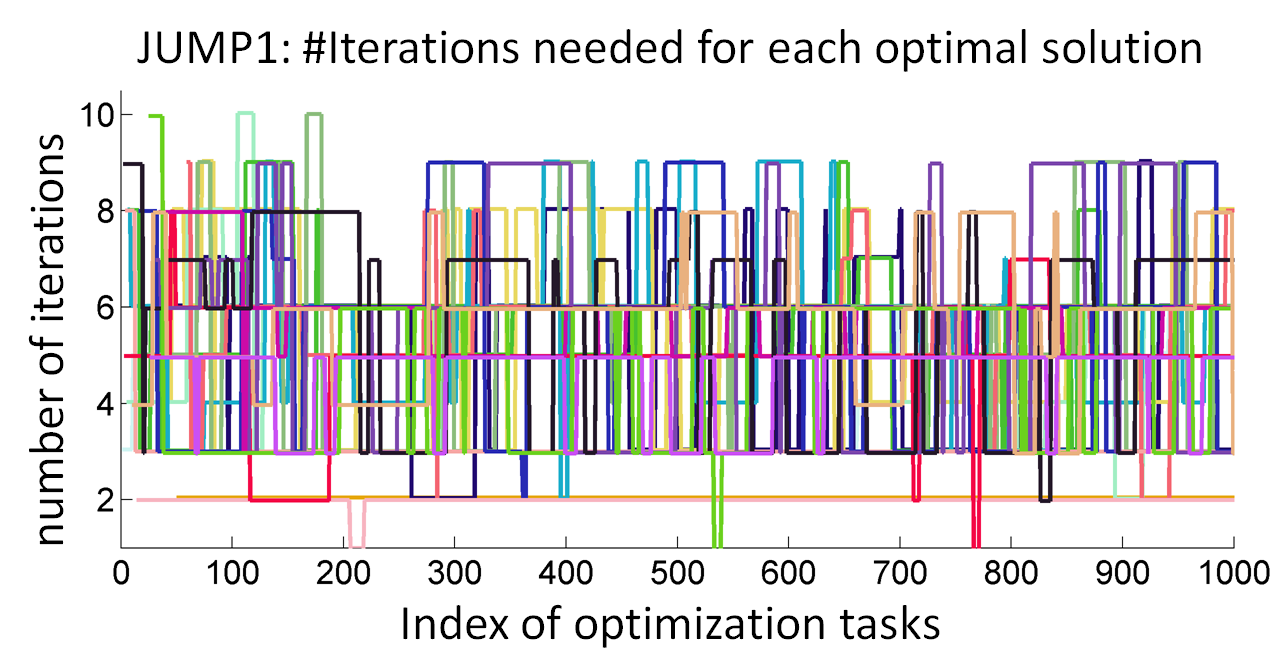
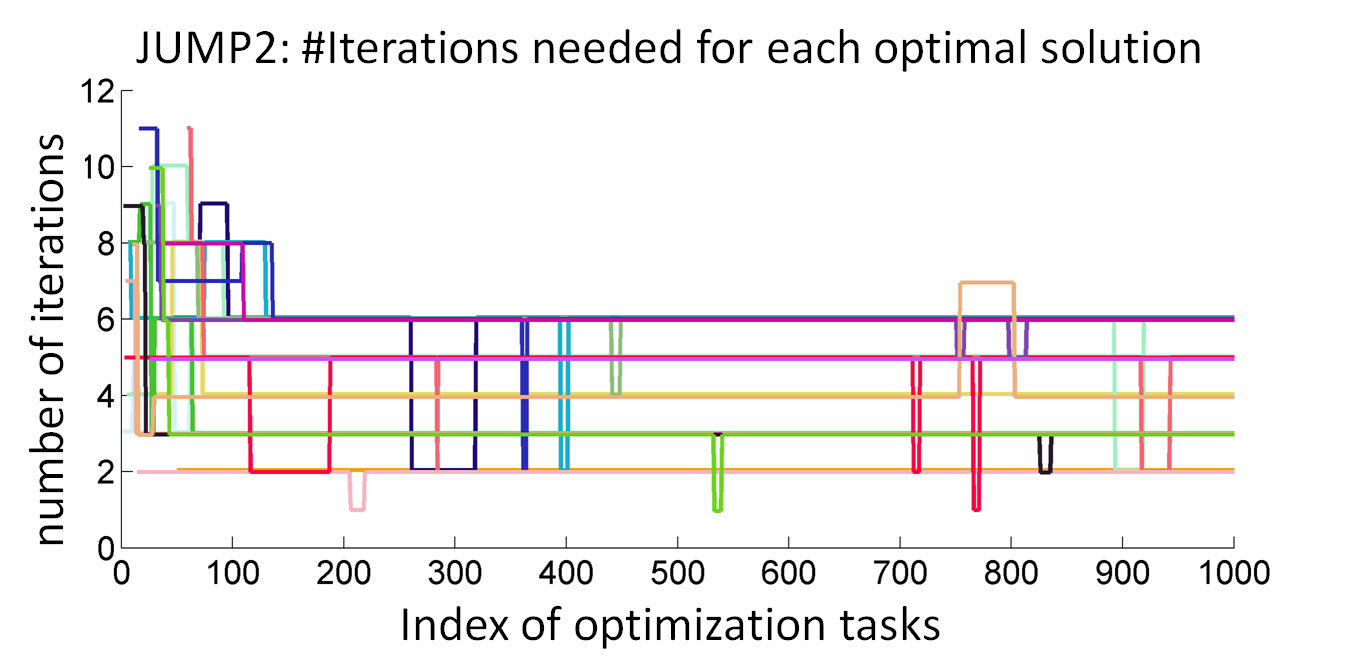
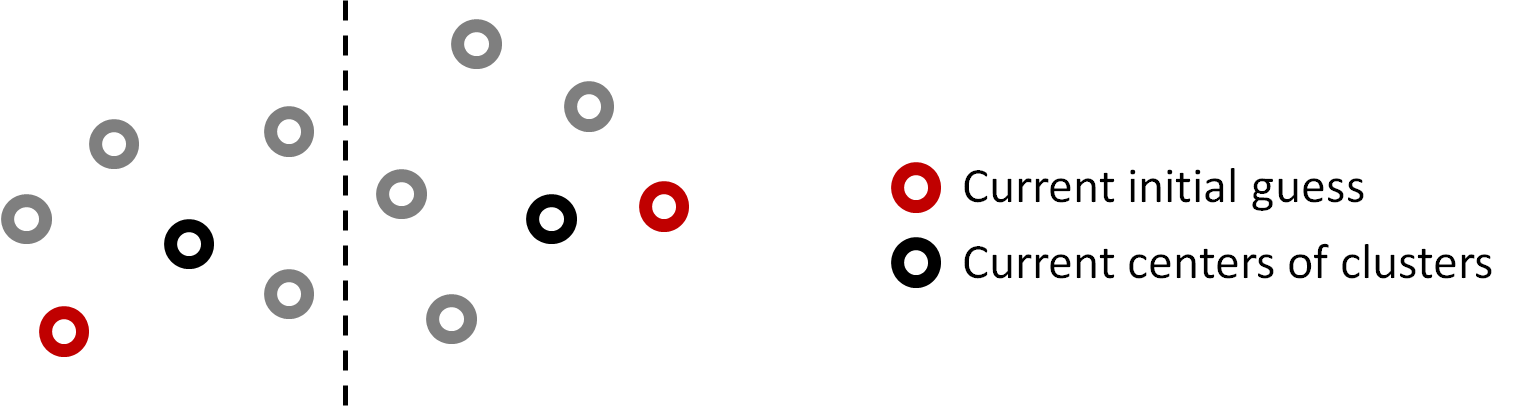
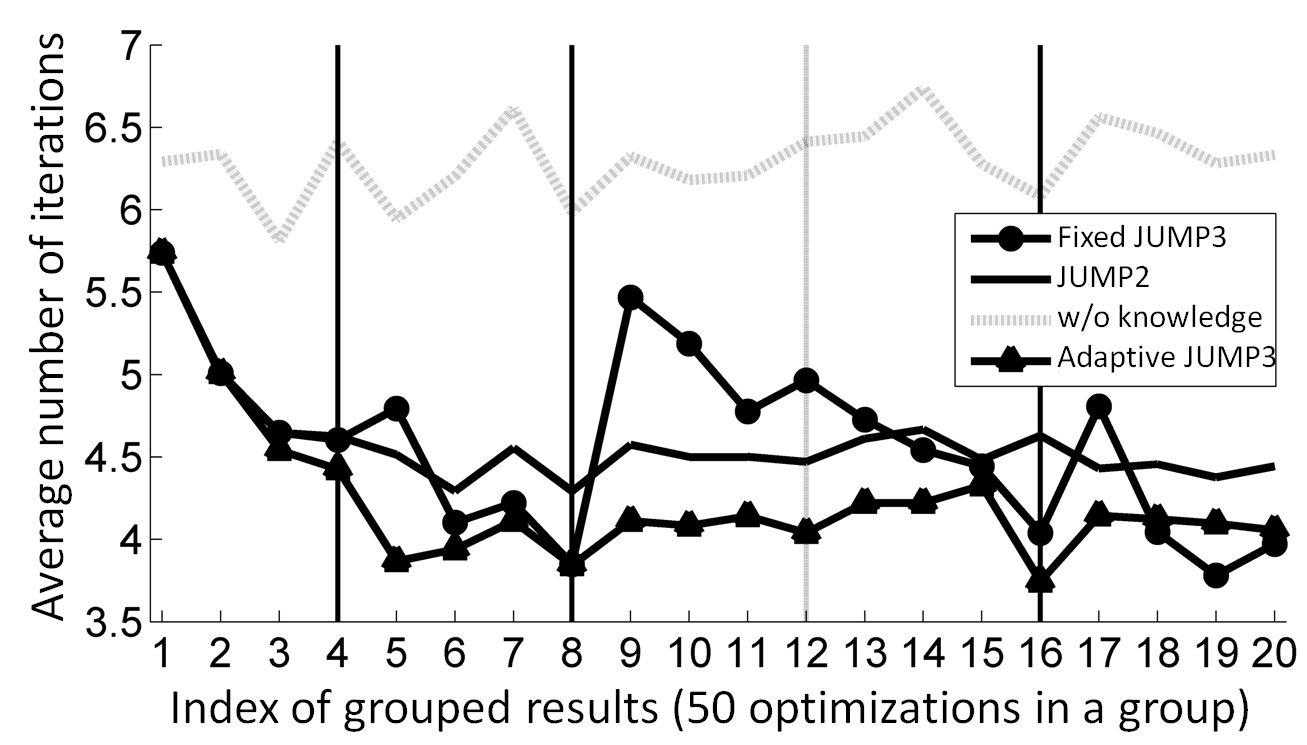
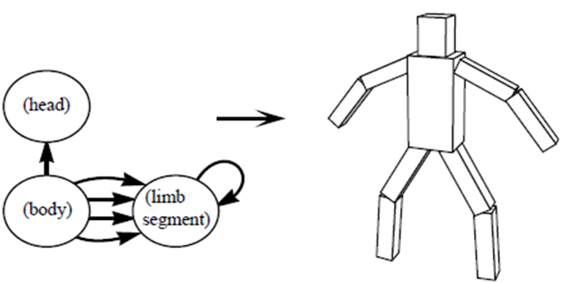
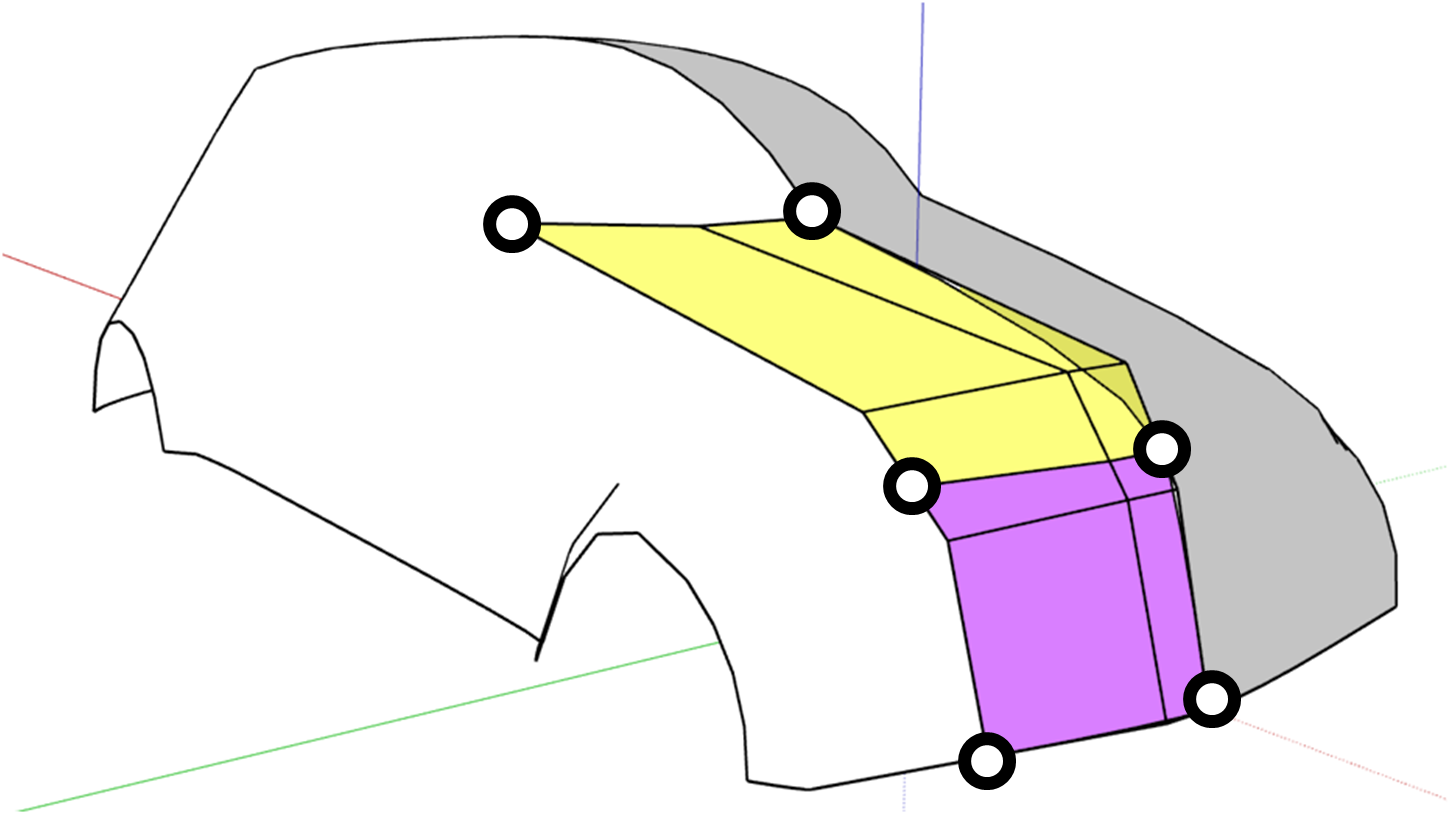
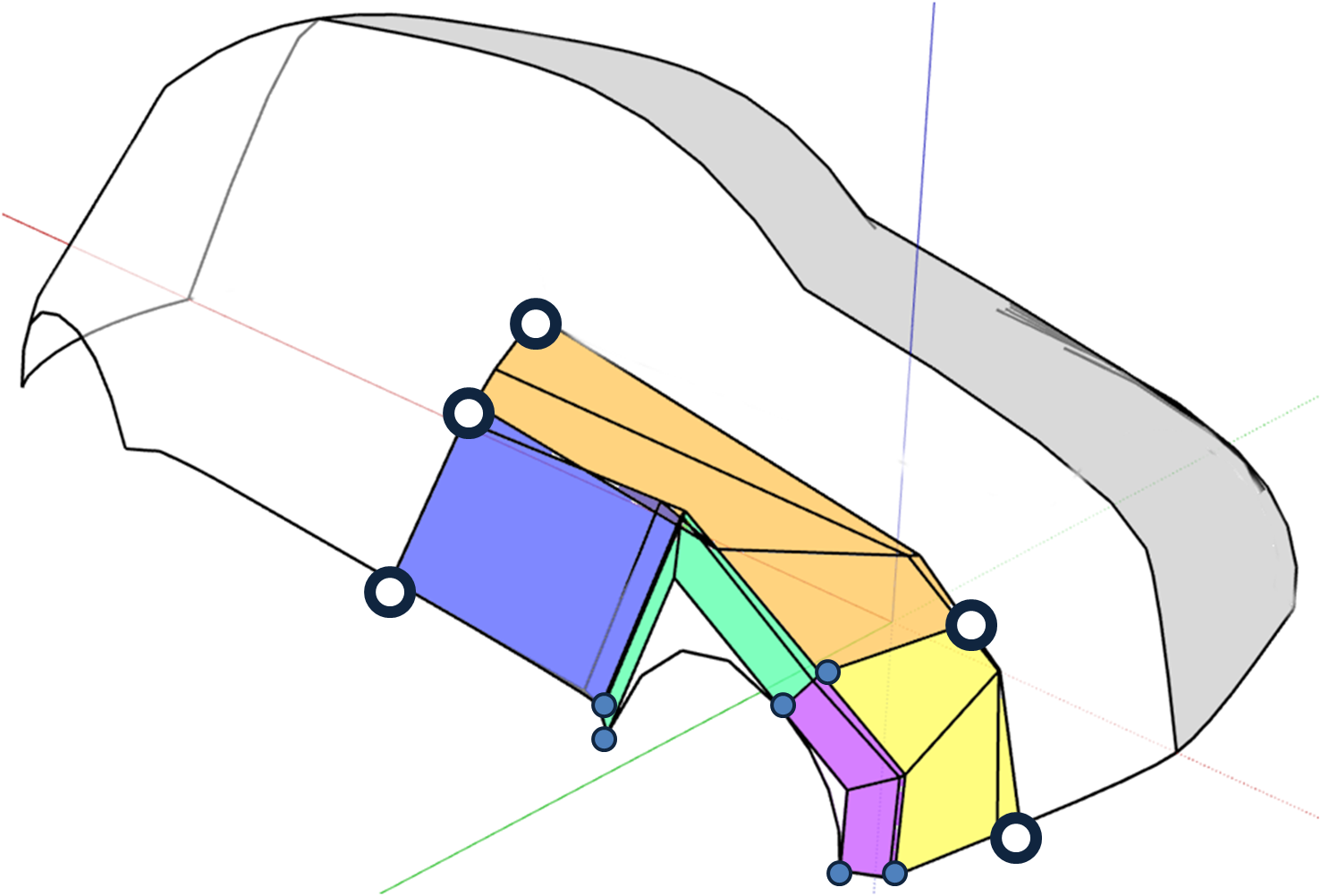
An RBF kernel is used to measure the similarity between two design differences:
$\begin{eqnarray}
K_{ij} && = \left\langle \Phi(x_{i_{1}})-\Phi(x_{i_{2}}),\Phi(x_{j_{1}})-\Phi(x_{j_{2}})\right\rangle\\
&& =k(x_{i_{1}},x_{j_{1}})+k(x_{i_{2}},x_{j_{2}})-k(x_{i_{1}},x_{j_{2}})-k(x_{i_{2}},x_{j_{1}}),
\end{eqnarray}$
where $k(x_i,x_j) = \exp(-||x_i-x_j||^2/p)$ and $p$ is the dimensionality of $x$.