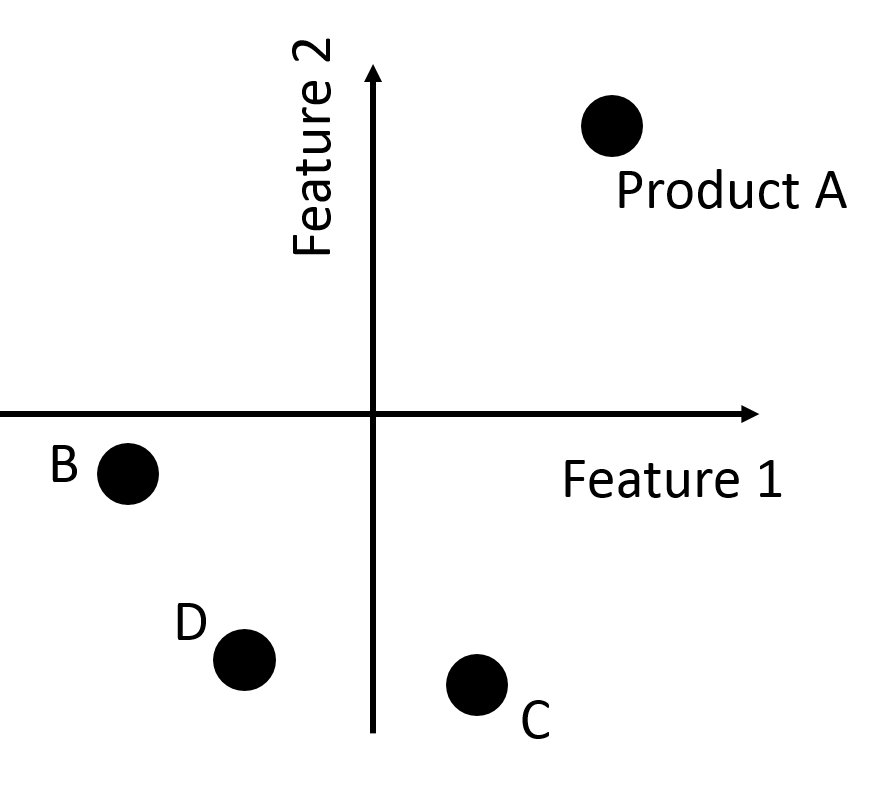
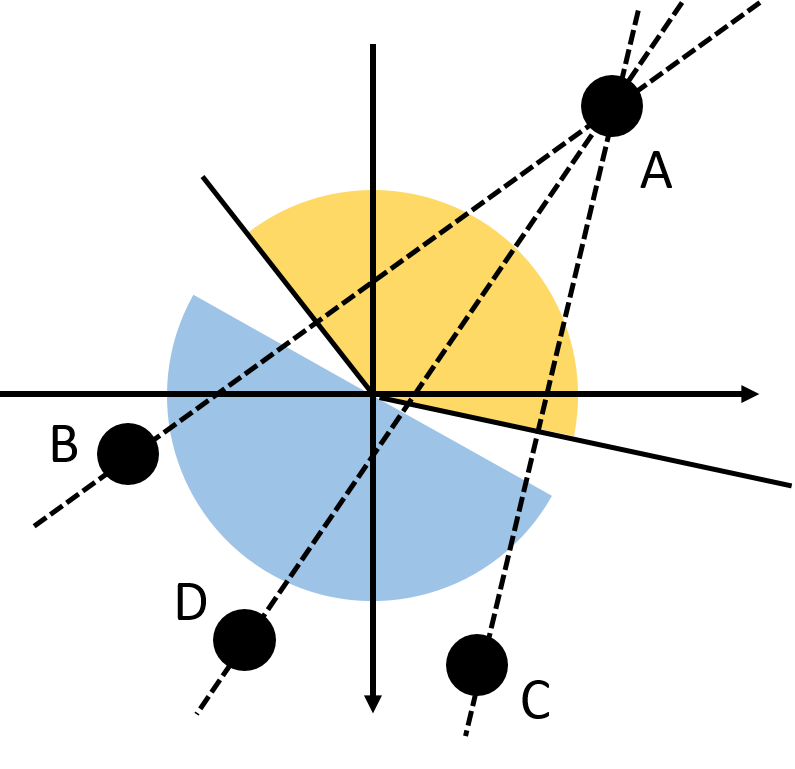
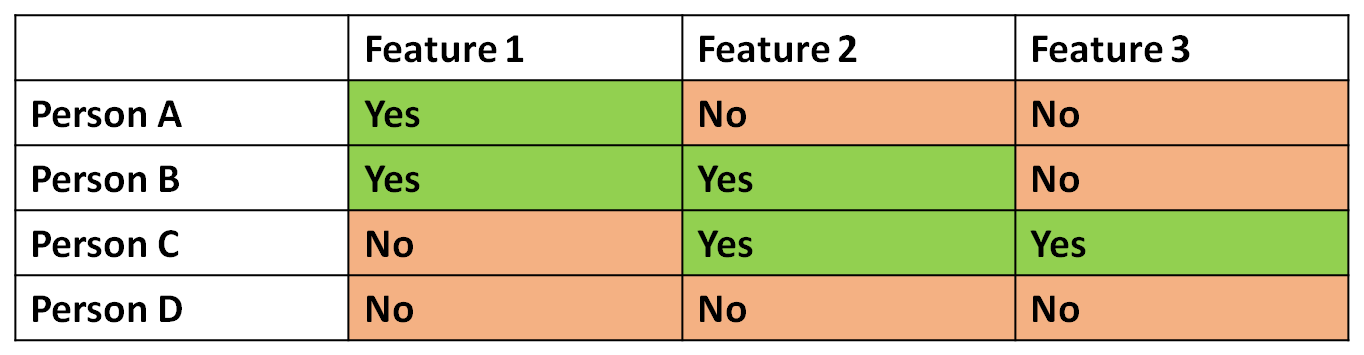
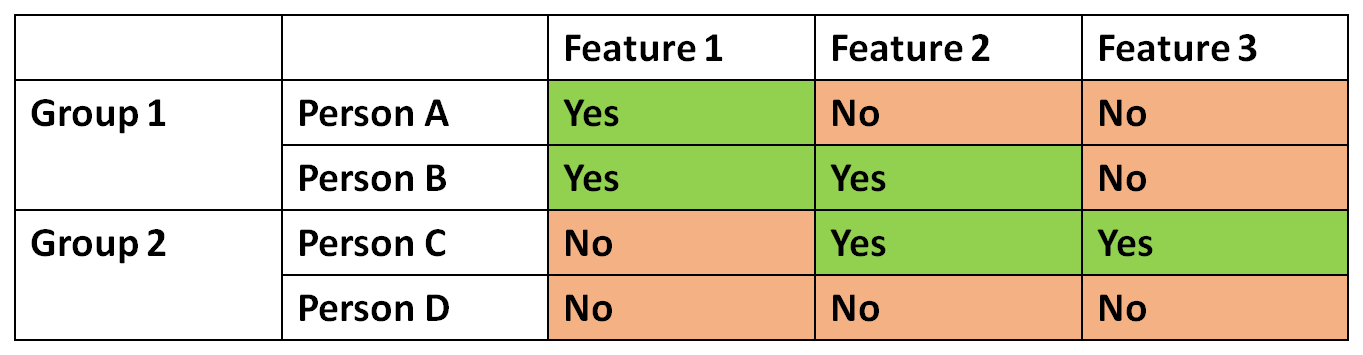
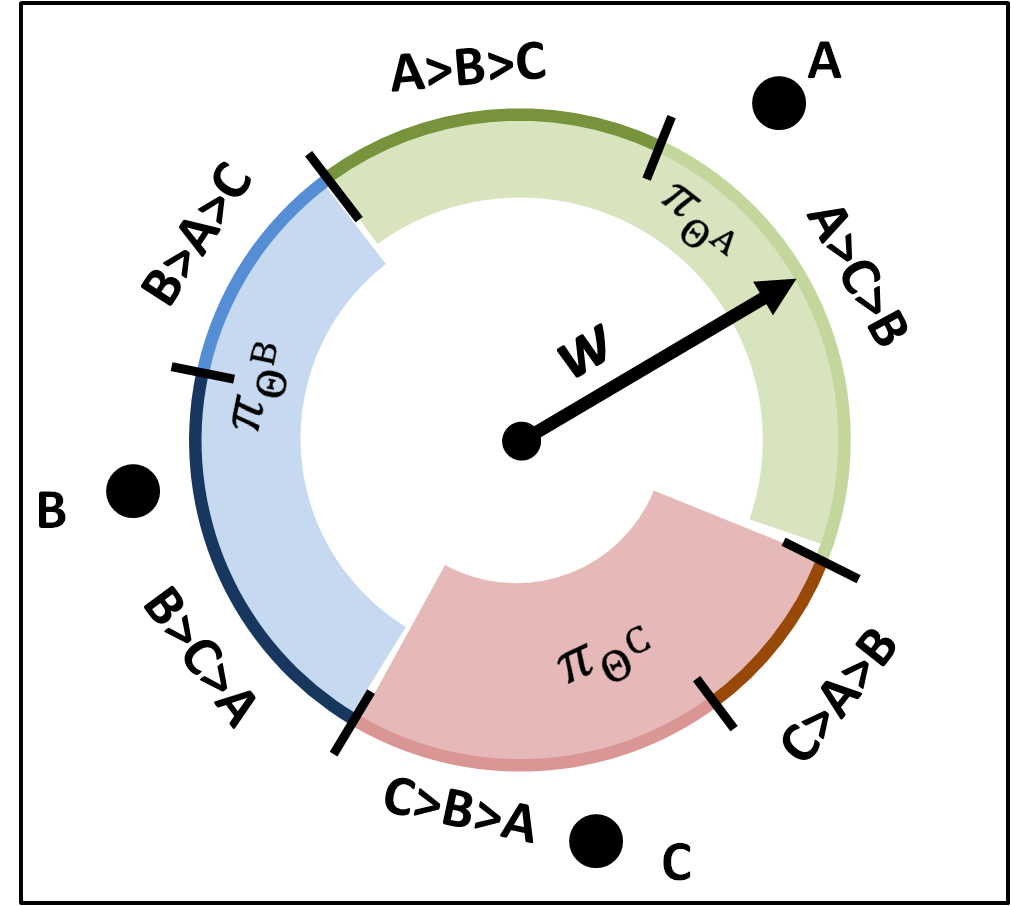
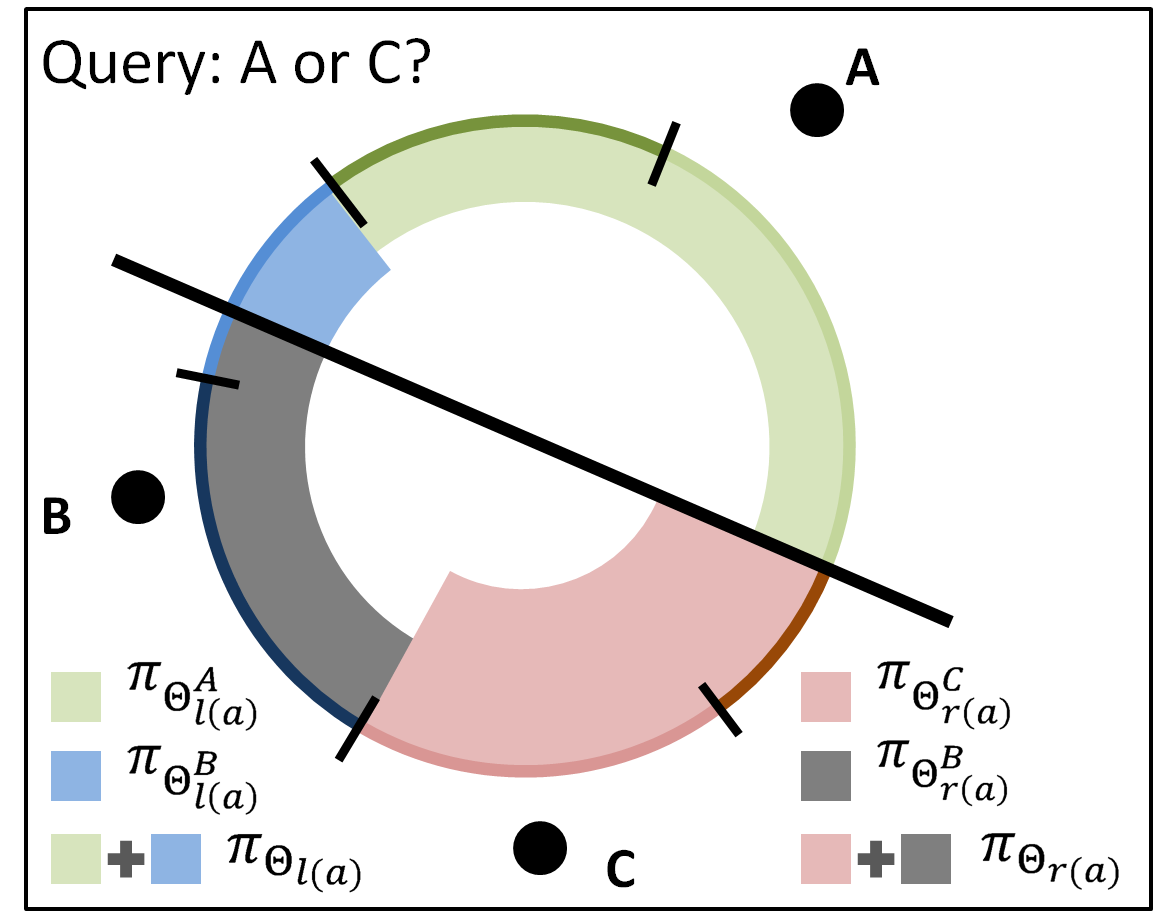
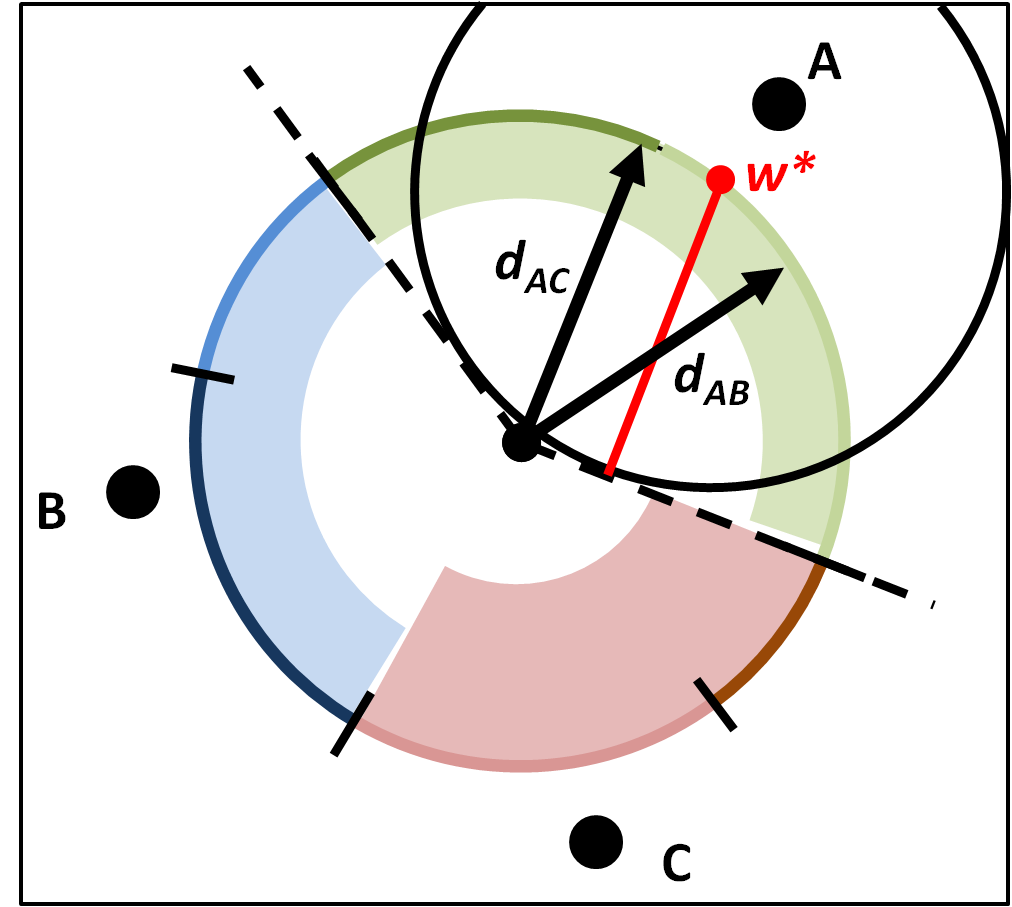
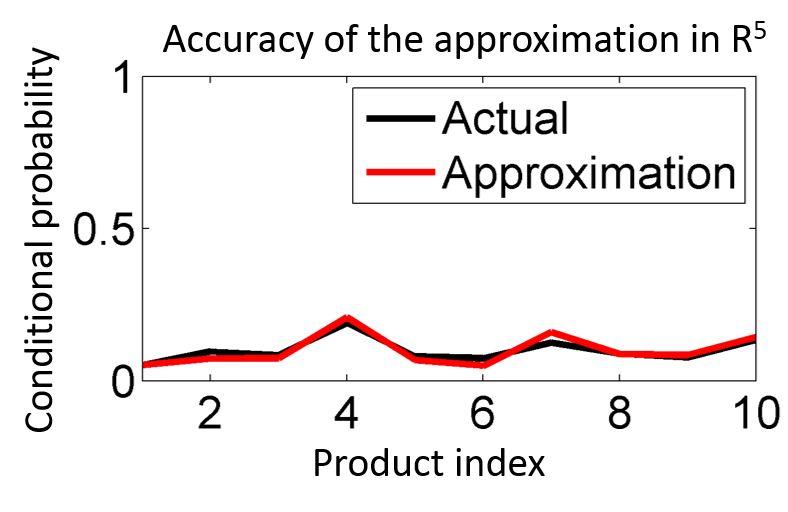
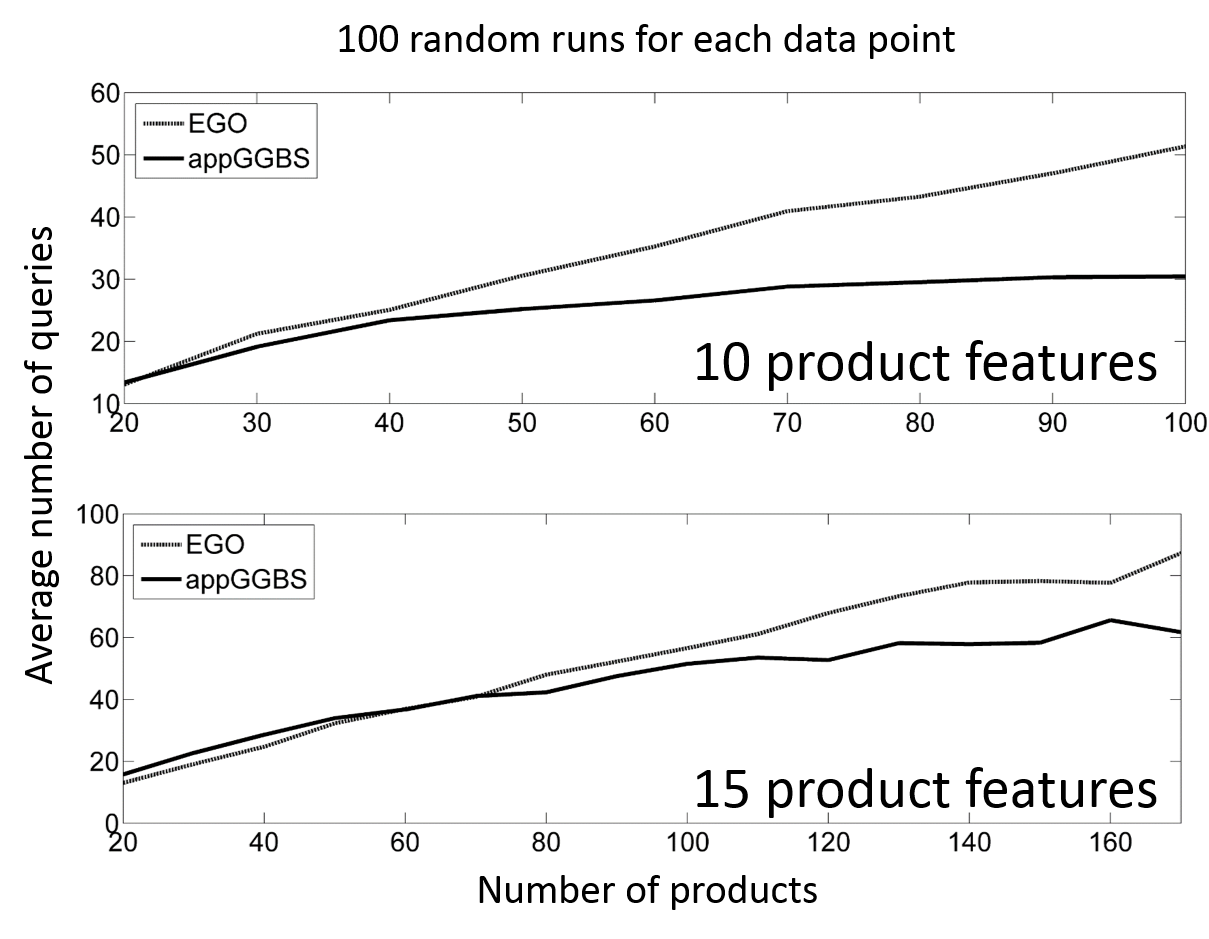
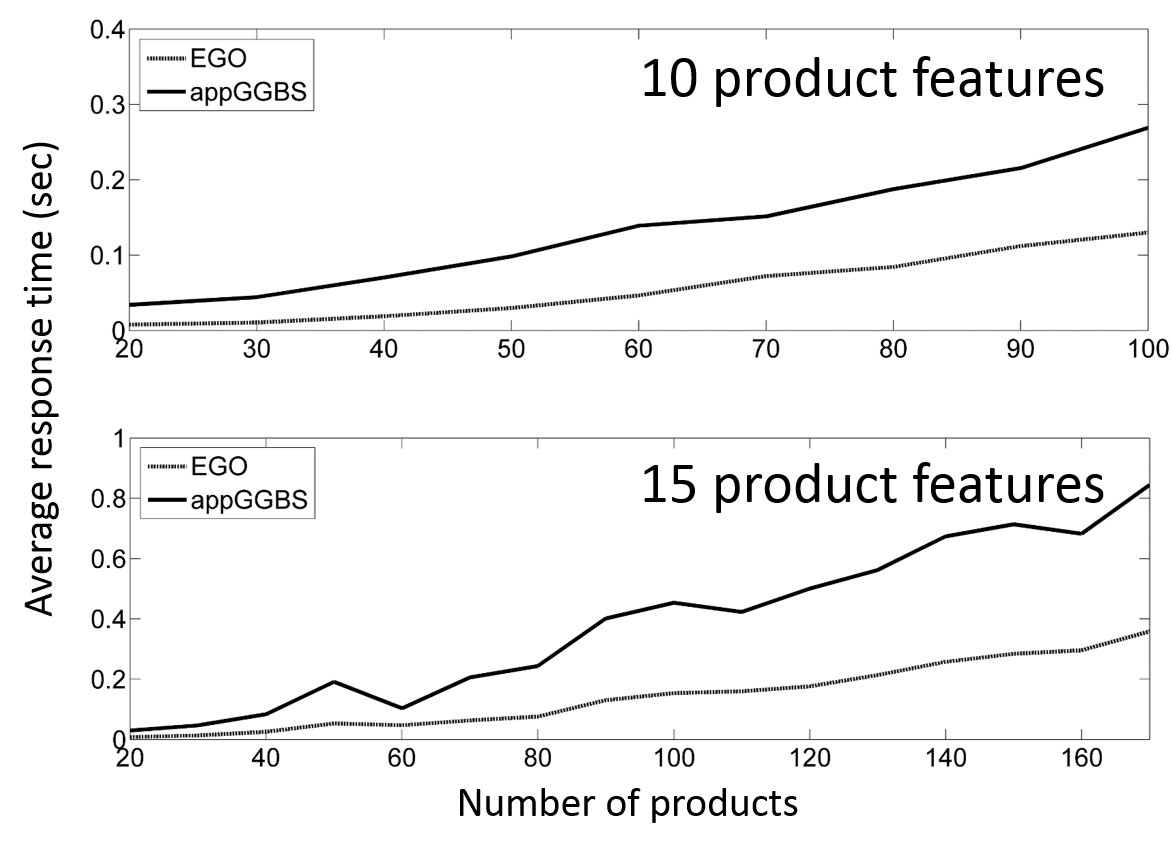
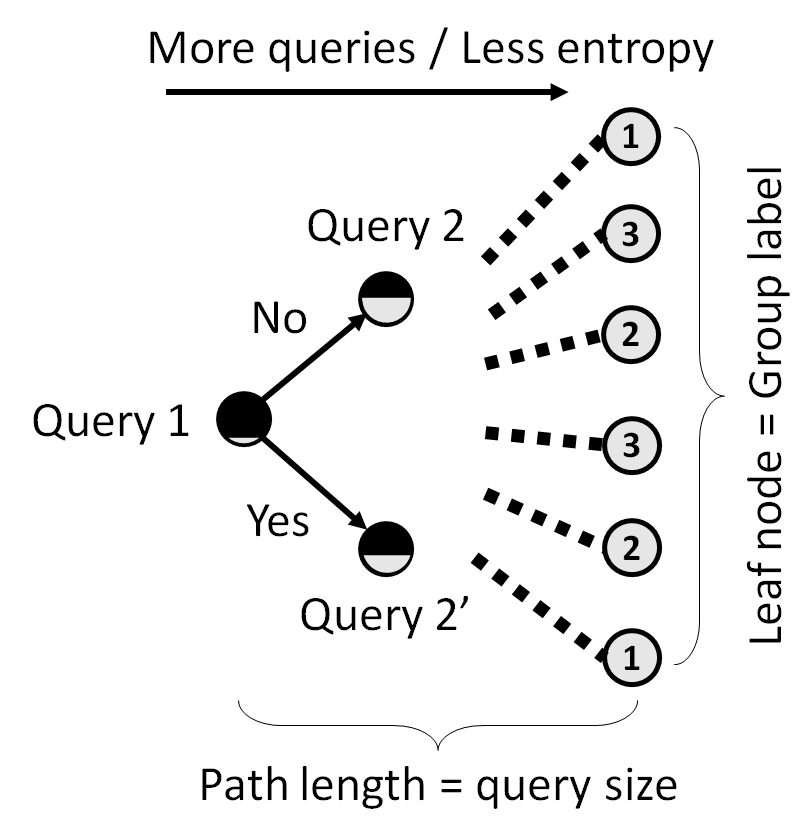
Demonstration of the problem



Research Fellow
Optimal Design Lab
University of Michigan
yiren@umich.edu
maxyiren.appspot.com

Associate Professor
Electrical Engineering and Computer Science
University of Michigan
clayscot@umich.edu
web.eecs.umich.edu/~cscott/

Professor
Optimal Design Lab
University of Michigan
pyp@umich.edu
ode.engin.umich.edu
/
#